* Support hybrid vector retrieval * Enable figures and table reading in Azure DI * Retrieve with multi-modal * Fix mixing up table * Add txt loader * Add Anthropic Chat * Raising error when retrieving help file * Allow same filename for different people if private is True * Allow declaring extra LLM vendors * Show chunks on the File page * Allow elasticsearch to get more docs * Fix Cohere response (#86) * Fix Cohere response * Remove Adobe pdfservice from dependency kotaemon doesn't rely more pdfservice for its core functionality, and pdfservice uses very out-dated dependency that causes conflict. --------- Co-authored-by: trducng <trungduc1992@gmail.com> * Add confidence score (#87) * Save question answering data as a log file * Save the original information besides the rewritten info * Export Cohere relevance score as confidence score * Fix style check * Upgrade the confidence score appearance (#90) * Highlight the relevance score * Round relevance score. Get key from config instead of env * Cohere return all scores * Display relevance score for image * Remove columns and rows in Excel loader which contains all NaN (#91) * remove columns and rows which contains all NaN * back to multiple joiner options * Fix style --------- Co-authored-by: linhnguyen-cinnamon <cinmc0019@CINMC0019-LinhNguyen.local> Co-authored-by: trducng <trungduc1992@gmail.com> * Track retriever state * Bump llama-index version 0.10 * feat/save-azuredi-mhtml-to-markdown (#93) * feat/save-azuredi-mhtml-to-markdown * fix: replace os.path to pathlib change theflow.settings * refactor: base on pre-commit * chore: move the func of saving content markdown above removed_spans --------- Co-authored-by: jacky0218 <jacky0218@github.com> * fix: losing first chunk (#94) * fix: losing first chunk. * fix: update the method of preventing losing chunks --------- Co-authored-by: jacky0218 <jacky0218@github.com> * fix: adding the base64 image in markdown (#95) * feat: more chunk info on UI * fix: error when reindexing files * refactor: allow more information exception trace when using gpt4v * feat: add excel reader that treats each worksheet as a document * Persist loader information when indexing file * feat: allow hiding unneeded setting panels * feat: allow specific timezone when creating conversation * feat: add more confidence score (#96) * Allow a list of rerankers * Export llm reranking score instead of filter with boolean * Get logprobs from LLMs * Rename cohere reranking score * Call 2 rerankers at once * Run QA pipeline for each chunk to get qa_score * Display more relevance scores * Define another LLMScoring instead of editing the original one * Export logprobs instead of probs * Call LLMScoring * Get qa_score only in the final answer * feat: replace text length with token in file list * ui: show index name instead of id in the settings * feat(ai): restrict the vision temperature * fix(ui): remove the misleading message about non-retrieved evidences * feat(ui): show the reasoning name and description in the reasoning setting page * feat(ui): show version on the main windows * feat(ui): show default llm name in the setting page * fix(conf): append the result of doc in llm_scoring (#97) * fix: constraint maximum number of images * feat(ui): allow filter file by name in file list page * Fix exceeding token length error for OpenAI embeddings by chunking then averaging (#99) * Average embeddings in case the text exceeds max size * Add docstring * fix: Allow empty string when calling embedding * fix: update trulens LLM ranking score for retrieval confidence, improve citation (#98) * Round when displaying not by default * Add LLMTrulens reranking model * Use llmtrulensscoring in pipeline * fix: update UI display for trulen score --------- Co-authored-by: taprosoft <tadashi@cinnamon.is> * feat: add question decomposition & few-shot rewrite pipeline (#89) * Create few-shot query-rewriting. Run and display the result in info_panel * Fix style check * Put the functions to separate modules * Add zero-shot question decomposition * Fix fewshot rewriting * Add default few-shot examples * Fix decompose question * Fix importing rewriting pipelines * fix: update decompose logic in fullQA pipeline --------- Co-authored-by: taprosoft <tadashi@cinnamon.is> * fix: add encoding utf-8 when save temporal markdown in vectorIndex (#101) * fix: improve retrieval pipeline and relevant score display (#102) * fix: improve retrieval pipeline by extending first round top_k with multiplier * fix: minor fix * feat: improve UI default settings and add quick switch option for pipeline * fix: improve agent logics (#103) * fix: improve agent progres display * fix: update retrieval logic * fix: UI display * fix: less verbose debug log * feat: add warning message for low confidence * fix: LLM scoring enabled by default * fix: minor update logics * fix: hotfix image citation * feat: update docx loader for handle merged table cells + handle zip file upload (#104) * feat: update docx loader for handle merged table cells * feat: handle zip file * refactor: pre-commit * fix: escape text in download UI * feat: optimize vector store query db (#105) * feat: optimize vector store query db * feat: add file_id to chroma metadatas * feat: remove unnecessary logs and update migrate script * feat: iterate through file index * fix: remove unused code --------- Co-authored-by: taprosoft <tadashi@cinnamon.is> * fix: add openai embedidng exponential back-off * fix: update import download_loader * refactor: codespell * fix: update some default settings * fix: update installation instruction * fix: default chunk length in simple QA * feat: add share converstation feature and enable retrieval history (#108) * feat: add share converstation feature and enable retrieval history * fix: update share conversation UI --------- Co-authored-by: taprosoft <tadashi@cinnamon.is> * fix: allow exponential backoff for failed OCR call (#109) * fix: update default prompt when no retrieval is used * fix: create embedding for long image chunks * fix: add exception handling for additional table retriever * fix: clean conversation & file selection UI * fix: elastic search with empty doc_ids * feat: add thumbnail PDF reader for quick multimodal QA * feat: add thumbnail handling logic in indexing * fix: UI text update * fix: PDF thumb loader page number logic * feat: add quick indexing pipeline and update UI * feat: add conv name suggestion * fix: minor UI change * feat: citation in thread * fix: add conv name suggestion in regen * chore: add assets for usage doc * chore: update usage doc * feat: pdf viewer (#110) * feat: update pdfviewer * feat: update missing files * fix: update rendering logic of infor panel * fix: improve thumbnail retrieval logic * fix: update PDF evidence rendering logic * fix: remove pdfjs built dist * fix: reduce thumbnail evidence count * chore: update gitignore * fix: add js event on chat msg select * fix: update css for viewer * fix: add env var for PDFJS prebuilt * fix: move language setting to reasoning utils --------- Co-authored-by: phv2312 <kat87yb@gmail.com> Co-authored-by: trducng <trungduc1992@gmail.com> * feat: graph rag (#116) * fix: reload server when add/delete index * fix: rework indexing pipeline to be able to disable vectorstore and splitter if needed * feat: add graphRAG index with plot view * fix: update requirement for graphRAG and lighten unnecessary packages * feat: add knowledge network index (#118) * feat: add Knowledge Network index * fix: update reader mode setting for knet * fix: update init knet * fix: update collection name to index pipeline * fix: missing req --------- Co-authored-by: jeff52415 <jeff.yang@cinnamon.is> * fix: update info panel return for graphrag * fix: retriever setting graphrag * feat: local llm settings (#122) * feat: expose context length as reasoning setting to better fit local models * fix: update context length setting for agents * fix: rework threadpool llm call * fix: fix improve indexing logic * fix: fix improve UI * feat: add lancedb * fix: improve lancedb logic * feat: add lancedb vectorstore * fix: lighten requirement * fix: improve lanceDB vs * fix: improve UI * fix: openai retry * fix: update reqs * fix: update launch command * feat: update Dockerfile * feat: add plot history * fix: update default config * fix: remove verbose print * fix: update default setting * fix: update gradio plot return * fix: default gradio tmp * fix: improve lancedb docstore * fix: fix question decompose pipeline * feat: add multimodal reader in UI * fix: udpate docs * fix: update default settings & docker build * fix: update app startup * chore: update documentation * chore: update README * chore: update README --------- Co-authored-by: trducng <trungduc1992@gmail.com> * chore: update README * chore: update README --------- Co-authored-by: trducng <trungduc1992@gmail.com> Co-authored-by: cin-ace <ace@cinnamon.is> Co-authored-by: Linh Nguyen <70562198+linhnguyen-cinnamon@users.noreply.github.com> Co-authored-by: linhnguyen-cinnamon <cinmc0019@CINMC0019-LinhNguyen.local> Co-authored-by: cin-jacky <101088014+jacky0218@users.noreply.github.com> Co-authored-by: jacky0218 <jacky0218@github.com> Co-authored-by: kan_cin <kan@cinnamon.is> Co-authored-by: phv2312 <kat87yb@gmail.com> Co-authored-by: jeff52415 <jeff.yang@cinnamon.is>
158 lines
6.5 KiB
Markdown
158 lines
6.5 KiB
Markdown
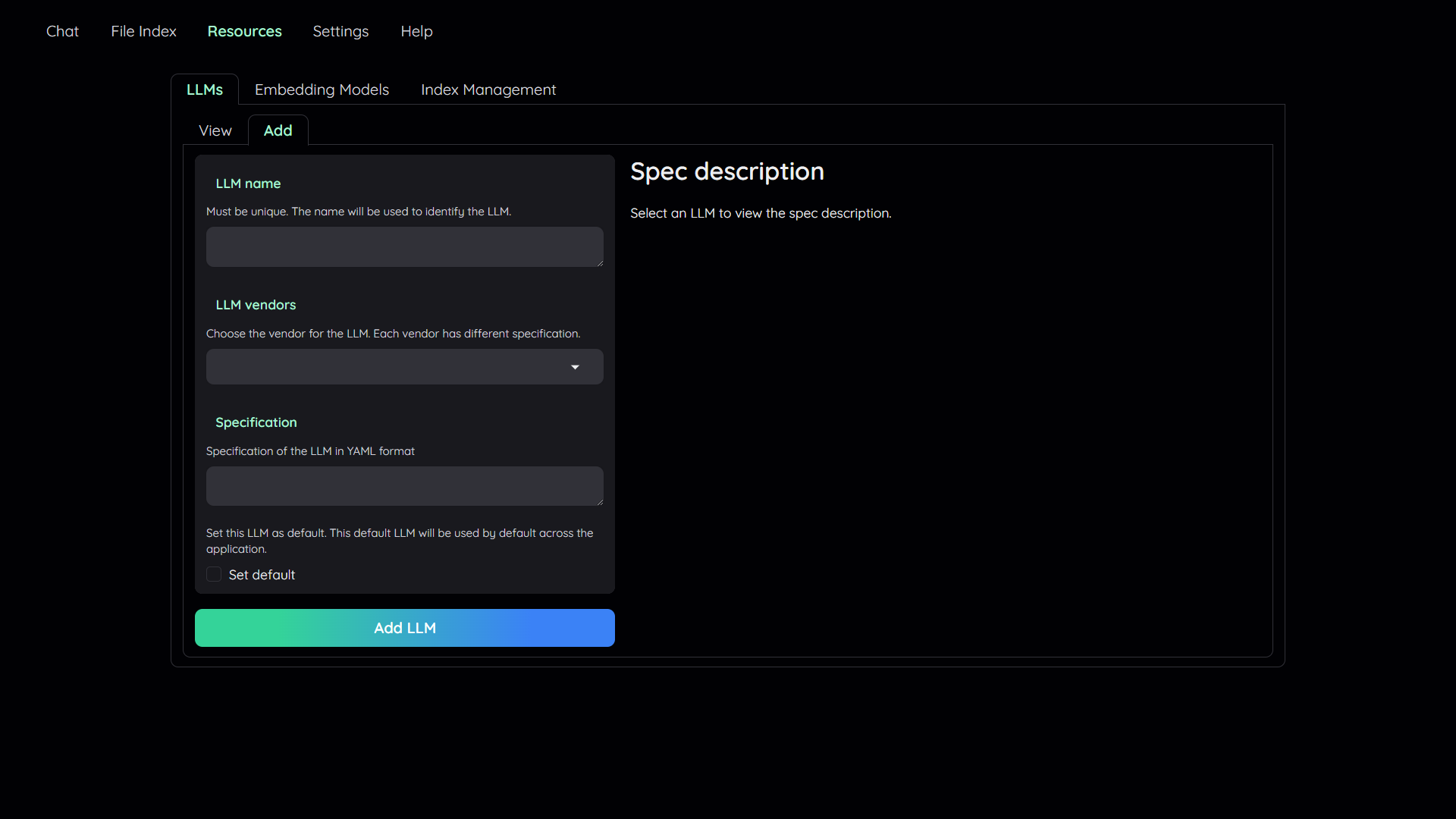
## 1. Add your AI models
|
|
|
|
|
|
|
|
- The tool uses Large Language Model (LLMs) to perform various tasks in a QA pipeline.
|
|
So, you need to provide the application with access to the LLMs you want
|
|
to use.
|
|
- You only need to provide at least one. However, tt is recommended that you include all the LLMs
|
|
that you have access to, you will be able to switch between them while using the
|
|
application.
|
|
|
|
To add a model:
|
|
|
|
1. Navigate to the `Resources` tab.
|
|
2. Select the `LLMs` sub-tab.
|
|
3. Select the `Add` sub-tab.
|
|
4. Config the model to add:
|
|
- Give it a name.
|
|
- Pick a vendor/provider (e.g. `ChatOpenAI`).
|
|
- Provide the specifications.
|
|
- (Optional) Set the model as default.
|
|
5. Click `Add` to add the model.
|
|
6. Select `Embedding Models` sub-tab and repeat the step 3 to 5 to add an embedding model.
|
|
|
|
<details markdown>
|
|
|
|
<summary>(Optional) Configure model via the .env file</summary>
|
|
|
|
Alternatively, you can configure the models via the `.env` file with the information needed to connect to the LLMs. This file is located in
|
|
the folder of the application. If you don't see it, you can create one.
|
|
|
|
Currently, the following providers are supported:
|
|
|
|
### OpenAI
|
|
|
|
In the `.env` file, set the `OPENAI_API_KEY` variable with your OpenAI API key in order
|
|
to enable access to OpenAI's models. There are other variables that can be modified,
|
|
please feel free to edit them to fit your case. Otherwise, the default parameter should
|
|
work for most people.
|
|
|
|
```shell
|
|
OPENAI_API_BASE=https://api.openai.com/v1
|
|
OPENAI_API_KEY=<your OpenAI API key here>
|
|
OPENAI_CHAT_MODEL=gpt-3.5-turbo
|
|
OPENAI_EMBEDDINGS_MODEL=text-embedding-ada-002
|
|
```
|
|
|
|
### Azure OpenAI
|
|
|
|
For OpenAI models via Azure platform, you need to provide your Azure endpoint and API
|
|
key. Your might also need to provide your developments' name for the chat model and the
|
|
embedding model depending on how you set up Azure development.
|
|
|
|
```shell
|
|
AZURE_OPENAI_ENDPOINT=
|
|
AZURE_OPENAI_API_KEY=
|
|
OPENAI_API_VERSION=2024-02-15-preview # could be different for you
|
|
AZURE_OPENAI_CHAT_DEPLOYMENT=gpt-35-turbo # change to your deployment name
|
|
AZURE_OPENAI_EMBEDDINGS_DEPLOYMENT=text-embedding-ada-002 # change to your deployment name
|
|
```
|
|
|
|
### Local models
|
|
|
|
Pros:
|
|
|
|
- Privacy. Your documents will be stored and process locally.
|
|
- Choices. There are a wide range of LLMs in terms of size, domain, language to choose
|
|
from.
|
|
- Cost. It's free.
|
|
|
|
Cons:
|
|
|
|
- Quality. Local models are much smaller and thus have lower generative quality than
|
|
paid APIs.
|
|
- Speed. Local models are deployed using your machine so the processing speed is
|
|
limited by your hardware.
|
|
|
|
#### Find and download a LLM
|
|
|
|
You can search and download a LLM to be ran locally from the [Hugging Face
|
|
Hub](https://huggingface.co/models). Currently, these model formats are supported:
|
|
|
|
- GGUF
|
|
|
|
You should choose a model whose size is less than your device's memory and should leave
|
|
about 2 GB. For example, if you have 16 GB of RAM in total, of which 12 GB is available,
|
|
then you should choose a model that take up at most 10 GB of RAM. Bigger models tend to
|
|
give better generation but also take more processing time.
|
|
|
|
Here are some recommendations and their size in memory:
|
|
|
|
- [Qwen1.5-1.8B-Chat-GGUF](https://huggingface.co/Qwen/Qwen1.5-1.8B-Chat-GGUF/resolve/main/qwen1_5-1_8b-chat-q8_0.gguf?download=true):
|
|
around 2 GB
|
|
|
|
#### Enable local models
|
|
|
|
To add a local model to the model pool, set the `LOCAL_MODEL` variable in the `.env`
|
|
file to the path of the model file.
|
|
|
|
```shell
|
|
LOCAL_MODEL=<full path to your model file>
|
|
```
|
|
|
|
Here is how to get the full path of your model file:
|
|
|
|
- On Windows 11: right click the file and select `Copy as Path`.
|
|
</details>
|
|
|
|
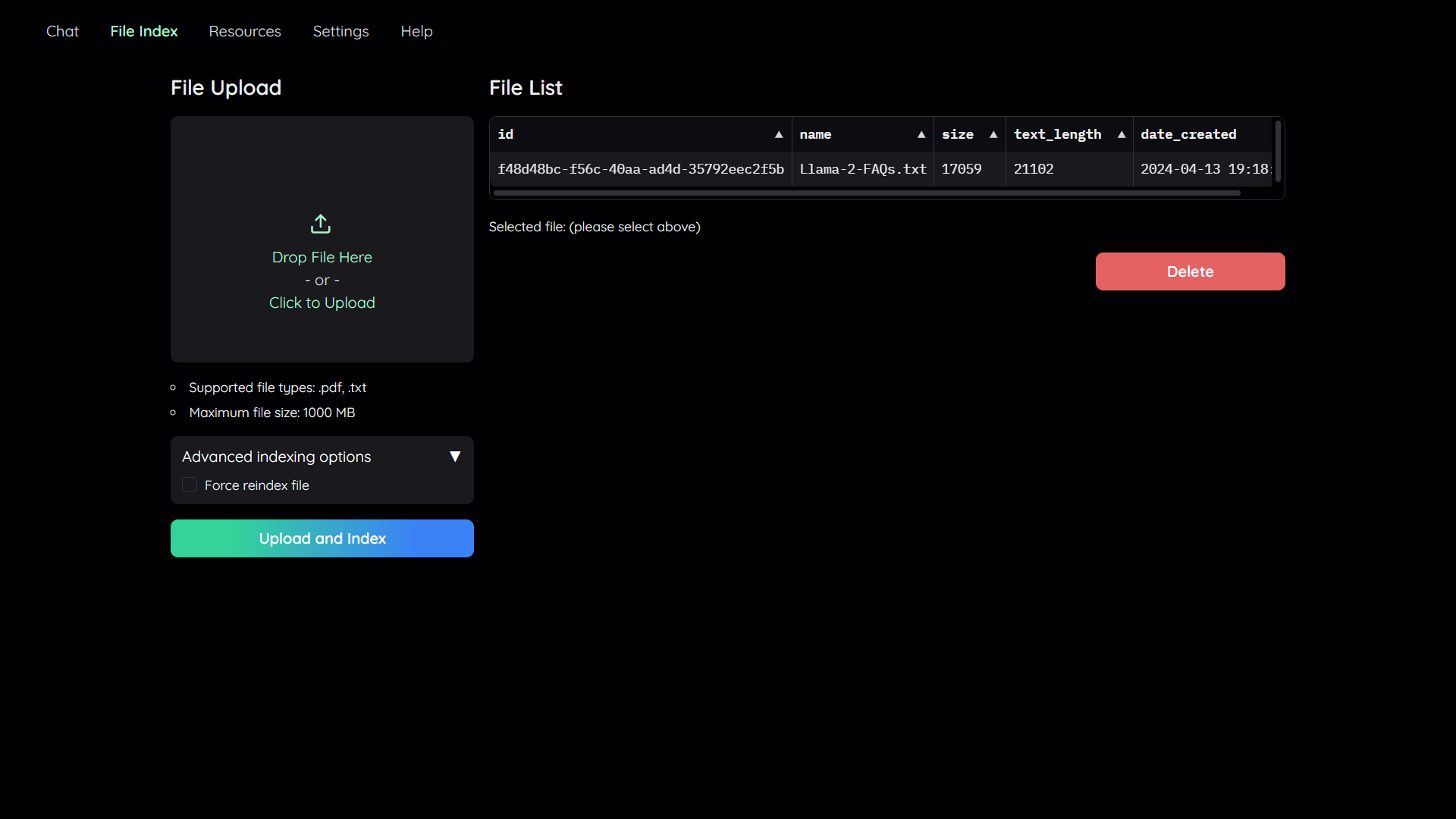
## 2. Upload your documents
|
|
|
|
|
|
|
|
In order to do QA on your documents, you need to upload them to the application first.
|
|
Navigate to the `File Index` tab and you will see 2 sections:
|
|
|
|
1. File upload:
|
|
- Drag and drop your file to the UI or select it from your file system.
|
|
Then click `Upload and Index`.
|
|
- The application will take some time to process the file and show a message once it is done.
|
|
2. File list:
|
|
- This section shows the list of files that have been uploaded to the application and allows users to delete them.
|
|
|
|
## 3. Chat with your documents
|
|
|
|

|
|
|
|
Now navigate back to the `Chat` tab. The chat tab is divided into 3 regions:
|
|
|
|
1. Conversation Settings Panel
|
|
- Here you can select, create, rename, and delete conversations.
|
|
- By default, a new conversation is created automatically if no conversation is selected.
|
|
- Below that you have the file index, where you can choose whether to disable, select all files, or select which files to retrieve references from.
|
|
- If you choose "Disabled", no files will be considered as context during chat.
|
|
- If you choose "Search All", all files will be considered during chat.
|
|
- If you choose "Select", a dropdown will appear for you to select the
|
|
files to be considered during chat. If no files are selected, then no
|
|
files will be considered during chat.
|
|
2. Chat Panel
|
|
- This is where you can chat with the chatbot.
|
|
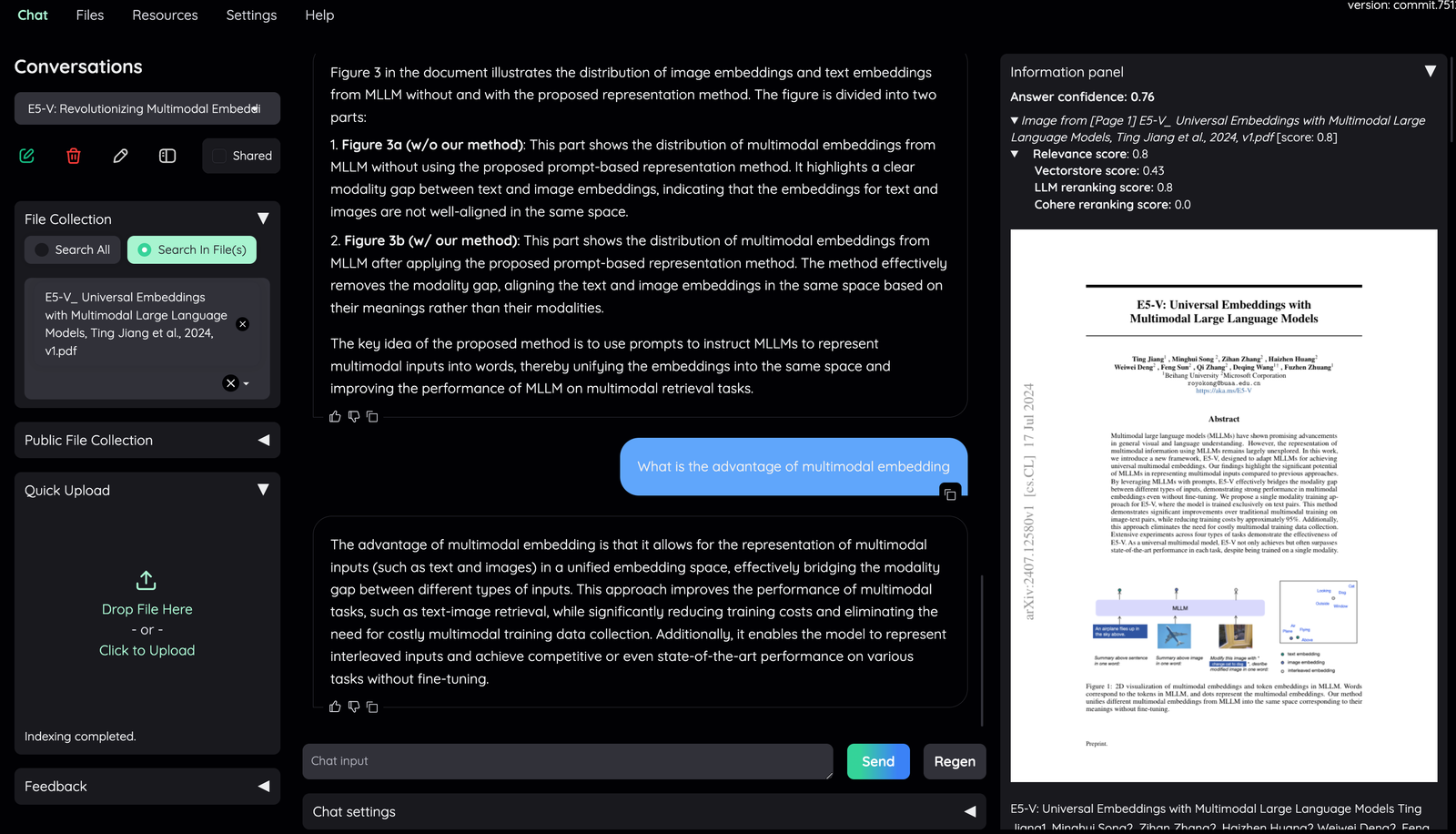
3. Information Panel
|
|
|
|
|
|
|
|
- Supporting information such as the retrieved evidence and reference will be
|
|
displayed here.
|
|
- Direct citation for the answer produced by the LLM is highlighted.
|
|
- The confidence score of the answer and relevant scores of evidences are displayed to quickly assess the quality of the answer and retrieved content.
|
|
|
|
- Meaning of the score displayed:
|
|
- **Answer confidence**: answer confidence level from the LLM model.
|
|
- **Relevance score**: overall relevant score between evidence and user question.
|
|
- **Vectorstore score**: relevant score from vector embedding similarity calculation (show `full-text search` if retrieved from full-text search DB).
|
|
- **LLM relevant score**: relevant score from LLM model (which judge relevancy between question and evidence using specific prompt).
|
|
- **Reranking score**: relevant score from Cohere [reranking model](https://cohere.com/rerank).
|
|
|
|
Generally, the score quality is `LLM relevant score` > `Reranking score` > `Vectorscore`.
|
|
By default, overall relevance score is taken directly from LLM relevant score. Evidences are sorted based on their overall relevance score and whether they have citation or not.
|