[AUR-432] Add layout-aware table parsing PDF reader (#27)
* add OCRReader, MathPixReader and ExcelReader * update test case for ocr reader * reformat * minor fix
This commit is contained in:
committed by
 GitHub
GitHub
parent
6207f4332a
commit
6c3d614973
@@ -47,5 +47,5 @@ repos:
|
|||||||
rev: "v1.5.1"
|
rev: "v1.5.1"
|
||||||
hooks:
|
hooks:
|
||||||
- id: mypy
|
- id: mypy
|
||||||
additional_dependencies: [types-PyYAML==6.0.12.11]
|
additional_dependencies: [types-PyYAML==6.0.12.11, "types-requests"]
|
||||||
args: ["--check-untyped-defs", "--ignore-missing-imports"]
|
args: ["--check-untyped-defs", "--ignore-missing-imports"]
|
||||||
|
|||||||
@@ -0,0 +1,3 @@
|
|||||||
|
from .base import Document
|
||||||
|
|
||||||
|
__all__ = ["Document"]
|
||||||
|
|||||||
@@ -1,3 +1,6 @@
|
|||||||
from .base import AutoReader
|
from .base import AutoReader
|
||||||
|
from .excel_loader import PandasExcelReader
|
||||||
|
from .mathpix_loader import MathpixPDFReader
|
||||||
|
from .ocr_loader import OCRReader
|
||||||
|
|
||||||
__all__ = ["AutoReader"]
|
__all__ = ["AutoReader", "PandasExcelReader", "MathpixPDFReader", "OCRReader"]
|
||||||
|
|||||||
96
knowledgehub/loaders/excel_loader.py
Normal file
96
knowledgehub/loaders/excel_loader.py
Normal file
@@ -0,0 +1,96 @@
|
|||||||
|
"""Pandas Excel reader.
|
||||||
|
|
||||||
|
Pandas parser for .xlsx files.
|
||||||
|
|
||||||
|
"""
|
||||||
|
from pathlib import Path
|
||||||
|
from typing import Any, List, Optional, Union
|
||||||
|
|
||||||
|
from llama_index.readers.base import BaseReader
|
||||||
|
|
||||||
|
from kotaemon.documents import Document
|
||||||
|
|
||||||
|
|
||||||
|
class PandasExcelReader(BaseReader):
|
||||||
|
r"""Pandas-based CSV parser.
|
||||||
|
|
||||||
|
Parses CSVs using the separator detection from Pandas `read_csv`function.
|
||||||
|
If special parameters are required, use the `pandas_config` dict.
|
||||||
|
|
||||||
|
Args:
|
||||||
|
|
||||||
|
pandas_config (dict): Options for the `pandas.read_excel` function call.
|
||||||
|
Refer to https://pandas.pydata.org/docs/reference/api/pandas.read_excel.html
|
||||||
|
for more information. Set to empty dict by default,
|
||||||
|
this means defaults will be used.
|
||||||
|
|
||||||
|
"""
|
||||||
|
|
||||||
|
def __init__(
|
||||||
|
self,
|
||||||
|
*args: Any,
|
||||||
|
pandas_config: Optional[dict] = None,
|
||||||
|
row_joiner: str = "\n",
|
||||||
|
**kwargs: Any,
|
||||||
|
) -> None:
|
||||||
|
"""Init params."""
|
||||||
|
super().__init__(*args, **kwargs)
|
||||||
|
self._pandas_config = pandas_config or {}
|
||||||
|
self._row_joiner = row_joiner if row_joiner else "\n"
|
||||||
|
|
||||||
|
def load_data(
|
||||||
|
self,
|
||||||
|
file: Path,
|
||||||
|
include_sheetname: bool = False,
|
||||||
|
sheet_name: Optional[Union[str, int, list]] = None,
|
||||||
|
**kwargs,
|
||||||
|
) -> List[Document]:
|
||||||
|
"""Parse file and extract values from a specific column.
|
||||||
|
|
||||||
|
Args:
|
||||||
|
file (Path): The path to the Excel file to read.
|
||||||
|
include_sheetname (bool): Whether to include the sheet name in the output.
|
||||||
|
sheet_name (Union[str, int, None]): The specific sheet to read from,
|
||||||
|
default is None which reads all sheets.
|
||||||
|
|
||||||
|
Returns:
|
||||||
|
List[Document]: A list of`Document objects containing the
|
||||||
|
values from the specified column in the Excel file.
|
||||||
|
"""
|
||||||
|
import itertools
|
||||||
|
|
||||||
|
try:
|
||||||
|
import pandas as pd
|
||||||
|
except ImportError:
|
||||||
|
raise ImportError(
|
||||||
|
"install pandas using `pip3 install pandas` to use this loader"
|
||||||
|
)
|
||||||
|
|
||||||
|
if sheet_name is not None:
|
||||||
|
sheet_name = (
|
||||||
|
[sheet_name] if not isinstance(sheet_name, list) else sheet_name
|
||||||
|
)
|
||||||
|
|
||||||
|
dfs = pd.read_excel(file, sheet_name=sheet_name, **self._pandas_config)
|
||||||
|
sheet_names = dfs.keys()
|
||||||
|
df_sheets = []
|
||||||
|
|
||||||
|
for key in sheet_names:
|
||||||
|
sheet = []
|
||||||
|
if include_sheetname:
|
||||||
|
sheet.append([key])
|
||||||
|
sheet.extend(dfs[key].values.astype(str).tolist())
|
||||||
|
df_sheets.append(sheet)
|
||||||
|
|
||||||
|
text_list = list(
|
||||||
|
itertools.chain.from_iterable(df_sheets)
|
||||||
|
) # flatten list of lists
|
||||||
|
|
||||||
|
output = [
|
||||||
|
Document(
|
||||||
|
text=self._row_joiner.join(" ".join(sublist) for sublist in text_list),
|
||||||
|
metadata={"source": file.stem},
|
||||||
|
)
|
||||||
|
]
|
||||||
|
|
||||||
|
return output
|
||||||
175
knowledgehub/loaders/mathpix_loader.py
Normal file
175
knowledgehub/loaders/mathpix_loader.py
Normal file
@@ -0,0 +1,175 @@
|
|||||||
|
import json
|
||||||
|
import re
|
||||||
|
import time
|
||||||
|
from pathlib import Path
|
||||||
|
from typing import Any, Dict, List
|
||||||
|
|
||||||
|
import requests
|
||||||
|
from langchain.utils import get_from_dict_or_env
|
||||||
|
from llama_index.readers.base import BaseReader
|
||||||
|
|
||||||
|
from kotaemon.documents import Document
|
||||||
|
|
||||||
|
from .utils.table import parse_markdown_text_to_tables, strip_special_chars_markdown
|
||||||
|
|
||||||
|
|
||||||
|
# MathpixPDFLoader implementation taken largely from Daniel Gross's:
|
||||||
|
# https://gist.github.com/danielgross/3ab4104e14faccc12b49200843adab21
|
||||||
|
class MathpixPDFReader(BaseReader):
|
||||||
|
"""Load `PDF` files using `Mathpix` service."""
|
||||||
|
|
||||||
|
def __init__(
|
||||||
|
self,
|
||||||
|
processed_file_format: str = "md",
|
||||||
|
max_wait_time_seconds: int = 500,
|
||||||
|
should_clean_pdf: bool = True,
|
||||||
|
**kwargs: Any,
|
||||||
|
) -> None:
|
||||||
|
"""Initialize with a file path.
|
||||||
|
|
||||||
|
Args:
|
||||||
|
processed_file_format: a format of the processed file. Default is "mmd".
|
||||||
|
max_wait_time_seconds: a maximum time to wait for the response from
|
||||||
|
the server. Default is 500.
|
||||||
|
should_clean_pdf: a flag to clean the PDF file. Default is False.
|
||||||
|
**kwargs: additional keyword arguments.
|
||||||
|
"""
|
||||||
|
self.mathpix_api_key = get_from_dict_or_env(
|
||||||
|
kwargs, "mathpix_api_key", "MATHPIX_API_KEY", default="empty"
|
||||||
|
)
|
||||||
|
self.mathpix_api_id = get_from_dict_or_env(
|
||||||
|
kwargs, "mathpix_api_id", "MATHPIX_API_ID", default="empty"
|
||||||
|
)
|
||||||
|
self.processed_file_format = processed_file_format
|
||||||
|
self.max_wait_time_seconds = max_wait_time_seconds
|
||||||
|
self.should_clean_pdf = should_clean_pdf
|
||||||
|
super().__init__()
|
||||||
|
|
||||||
|
@property
|
||||||
|
def _mathpix_headers(self) -> Dict[str, str]:
|
||||||
|
return {"app_id": self.mathpix_api_id, "app_key": self.mathpix_api_key}
|
||||||
|
|
||||||
|
@property
|
||||||
|
def url(self) -> str:
|
||||||
|
return "https://api.mathpix.com/v3/pdf"
|
||||||
|
|
||||||
|
@property
|
||||||
|
def data(self) -> dict:
|
||||||
|
options = {
|
||||||
|
"conversion_formats": {self.processed_file_format: True},
|
||||||
|
"enable_tables_fallback": True,
|
||||||
|
}
|
||||||
|
return {"options_json": json.dumps(options)}
|
||||||
|
|
||||||
|
def send_pdf(self, file_path) -> str:
|
||||||
|
with open(file_path, "rb") as f:
|
||||||
|
files = {"file": f}
|
||||||
|
response = requests.post(
|
||||||
|
self.url, headers=self._mathpix_headers, files=files, data=self.data
|
||||||
|
)
|
||||||
|
response_data = response.json()
|
||||||
|
if "pdf_id" in response_data:
|
||||||
|
pdf_id = response_data["pdf_id"]
|
||||||
|
return pdf_id
|
||||||
|
else:
|
||||||
|
raise ValueError("Unable to send PDF to Mathpix.")
|
||||||
|
|
||||||
|
def wait_for_processing(self, pdf_id: str) -> None:
|
||||||
|
"""Wait for processing to complete.
|
||||||
|
|
||||||
|
Args:
|
||||||
|
pdf_id: a PDF id.
|
||||||
|
|
||||||
|
Returns: None
|
||||||
|
"""
|
||||||
|
url = self.url + "/" + pdf_id
|
||||||
|
for _ in range(0, self.max_wait_time_seconds, 5):
|
||||||
|
response = requests.get(url, headers=self._mathpix_headers)
|
||||||
|
response_data = response.json()
|
||||||
|
status = response_data.get("status", None)
|
||||||
|
|
||||||
|
if status == "completed":
|
||||||
|
return
|
||||||
|
elif status == "error":
|
||||||
|
raise ValueError("Unable to retrieve PDF from Mathpix")
|
||||||
|
else:
|
||||||
|
print(response_data)
|
||||||
|
print(url)
|
||||||
|
time.sleep(5)
|
||||||
|
raise TimeoutError
|
||||||
|
|
||||||
|
def get_processed_pdf(self, pdf_id: str) -> str:
|
||||||
|
self.wait_for_processing(pdf_id)
|
||||||
|
url = f"{self.url}/{pdf_id}.{self.processed_file_format}"
|
||||||
|
response = requests.get(url, headers=self._mathpix_headers)
|
||||||
|
return response.content.decode("utf-8")
|
||||||
|
|
||||||
|
def clean_pdf(self, contents: str) -> str:
|
||||||
|
"""Clean the PDF file.
|
||||||
|
|
||||||
|
Args:
|
||||||
|
contents: a PDF file contents.
|
||||||
|
|
||||||
|
Returns:
|
||||||
|
|
||||||
|
"""
|
||||||
|
contents = "\n".join(
|
||||||
|
[line for line in contents.split("\n") if not line.startswith("![]")]
|
||||||
|
)
|
||||||
|
# replace \section{Title} with # Title
|
||||||
|
contents = contents.replace("\\section{", "# ")
|
||||||
|
# replace the "\" slash that Mathpix adds to escape $, %, (, etc.
|
||||||
|
|
||||||
|
# http:// or https:// followed by anything but a closing paren
|
||||||
|
url_regex = "http[s]?://[^)]+"
|
||||||
|
markup_regex = r"\[]\(\s*({0})\s*\)".format(url_regex)
|
||||||
|
contents = (
|
||||||
|
contents.replace(r"\$", "$")
|
||||||
|
.replace(r"\%", "%")
|
||||||
|
.replace(r"\(", "(")
|
||||||
|
.replace(r"\)", ")")
|
||||||
|
.replace("$\\begin{array}", "")
|
||||||
|
.replace("\\end{array}$", "")
|
||||||
|
.replace("\\\\", "")
|
||||||
|
.replace("\\text", "")
|
||||||
|
.replace("}", "")
|
||||||
|
.replace("{", "")
|
||||||
|
.replace("\\mathrm", "")
|
||||||
|
)
|
||||||
|
contents = re.sub(markup_regex, "", contents)
|
||||||
|
return contents
|
||||||
|
|
||||||
|
def load_data(self, file_path: Path, **kwargs) -> List[Document]:
|
||||||
|
if "response_content" in kwargs:
|
||||||
|
# overriding response content if specified
|
||||||
|
content = kwargs["response_content"]
|
||||||
|
else:
|
||||||
|
# call original API
|
||||||
|
pdf_id = self.send_pdf(file_path)
|
||||||
|
content = self.get_processed_pdf(pdf_id)
|
||||||
|
|
||||||
|
if self.should_clean_pdf:
|
||||||
|
content = self.clean_pdf(content)
|
||||||
|
tables, texts = parse_markdown_text_to_tables(content)
|
||||||
|
documents = []
|
||||||
|
for table in tables:
|
||||||
|
text = strip_special_chars_markdown(table)
|
||||||
|
metadata = {
|
||||||
|
"source": file_path.name,
|
||||||
|
"table_origin": table,
|
||||||
|
"type": "table",
|
||||||
|
}
|
||||||
|
documents.append(
|
||||||
|
Document(
|
||||||
|
text=text,
|
||||||
|
metadata=metadata,
|
||||||
|
metadata_template="",
|
||||||
|
metadata_seperator="",
|
||||||
|
)
|
||||||
|
)
|
||||||
|
|
||||||
|
for text in texts:
|
||||||
|
metadata = {"source": file_path.name, "type": "text"}
|
||||||
|
documents.append(Document(text=text, metadata=metadata))
|
||||||
|
|
||||||
|
return documents
|
||||||
97
knowledgehub/loaders/ocr_loader.py
Normal file
97
knowledgehub/loaders/ocr_loader.py
Normal file
@@ -0,0 +1,97 @@
|
|||||||
|
from pathlib import Path
|
||||||
|
from typing import List
|
||||||
|
from uuid import uuid4
|
||||||
|
|
||||||
|
import requests
|
||||||
|
from llama_index.readers.base import BaseReader
|
||||||
|
|
||||||
|
from kotaemon.documents import Document
|
||||||
|
|
||||||
|
from .utils.table import (
|
||||||
|
extract_tables_from_csv_string,
|
||||||
|
get_table_from_ocr,
|
||||||
|
strip_special_chars_markdown,
|
||||||
|
)
|
||||||
|
|
||||||
|
DEFAULT_OCR_ENDPOINT = "http://127.0.0.1:8000/v2/ai/infer/"
|
||||||
|
|
||||||
|
|
||||||
|
class OCRReader(BaseReader):
|
||||||
|
def __init__(self, endpoint: str = DEFAULT_OCR_ENDPOINT):
|
||||||
|
"""Init the OCR reader with OCR endpoint (FullOCR pipeline)
|
||||||
|
|
||||||
|
Args:
|
||||||
|
endpoint: URL to FullOCR endpoint. Defaults to OCR_ENDPOINT.
|
||||||
|
"""
|
||||||
|
super().__init__()
|
||||||
|
self.ocr_endpoint = endpoint
|
||||||
|
|
||||||
|
def load_data(
|
||||||
|
self,
|
||||||
|
file: Path,
|
||||||
|
**kwargs,
|
||||||
|
) -> List[Document]:
|
||||||
|
|
||||||
|
# create input params for the requests
|
||||||
|
content = open(file, "rb")
|
||||||
|
files = {"input": content}
|
||||||
|
data = {"job_id": uuid4()}
|
||||||
|
|
||||||
|
# init list of output documents
|
||||||
|
documents = []
|
||||||
|
all_table_csv_list = []
|
||||||
|
all_non_table_texts = []
|
||||||
|
|
||||||
|
# call the API from FullOCR endpoint
|
||||||
|
if "response_content" in kwargs:
|
||||||
|
# overriding response content if specified
|
||||||
|
results = kwargs["response_content"]
|
||||||
|
else:
|
||||||
|
# call original API
|
||||||
|
resp = requests.post(url=self.ocr_endpoint, files=files, data=data)
|
||||||
|
results = resp.json()["result"]
|
||||||
|
|
||||||
|
for _id, each in enumerate(results):
|
||||||
|
csv_content = each["csv_string"]
|
||||||
|
table = each["json"]["table"]
|
||||||
|
ocr = each["json"]["ocr"]
|
||||||
|
|
||||||
|
# using helper function to extract list of table texts from FullOCR output
|
||||||
|
table_texts = get_table_from_ocr(ocr, table)
|
||||||
|
# extract the formatted CSV table from specified text
|
||||||
|
csv_list, non_table_text = extract_tables_from_csv_string(
|
||||||
|
csv_content, table_texts
|
||||||
|
)
|
||||||
|
all_table_csv_list.extend([(csv, _id) for csv in csv_list])
|
||||||
|
all_non_table_texts.append((non_table_text, _id))
|
||||||
|
|
||||||
|
# create output Document with metadata from table
|
||||||
|
documents = [
|
||||||
|
Document(
|
||||||
|
text=strip_special_chars_markdown(csv),
|
||||||
|
metadata={
|
||||||
|
"table_origin": csv,
|
||||||
|
"type": "table",
|
||||||
|
"page_label": page_id + 1,
|
||||||
|
"source": file.name,
|
||||||
|
},
|
||||||
|
metadata_template="",
|
||||||
|
metadata_seperator="",
|
||||||
|
)
|
||||||
|
for csv, page_id in all_table_csv_list
|
||||||
|
]
|
||||||
|
# create Document from non-table text
|
||||||
|
documents.extend(
|
||||||
|
[
|
||||||
|
Document(
|
||||||
|
text=non_table_text,
|
||||||
|
metadata={
|
||||||
|
"page_label": page_id + 1,
|
||||||
|
"source": file.name,
|
||||||
|
},
|
||||||
|
)
|
||||||
|
for non_table_text, page_id in all_non_table_texts
|
||||||
|
]
|
||||||
|
)
|
||||||
|
|
||||||
|
return documents
|
||||||
0
knowledgehub/loaders/utils/__init__.py
Normal file
0
knowledgehub/loaders/utils/__init__.py
Normal file
335
knowledgehub/loaders/utils/table.py
Normal file
335
knowledgehub/loaders/utils/table.py
Normal file
@@ -0,0 +1,335 @@
|
|||||||
|
import csv
|
||||||
|
from io import StringIO
|
||||||
|
from typing import List, Optional, Tuple
|
||||||
|
|
||||||
|
|
||||||
|
def check_col_conflicts(
|
||||||
|
col_a: List[str], col_b: List[str], thres: float = 0.15
|
||||||
|
) -> bool:
|
||||||
|
"""Check if 2 columns A and B has non-empty content in the same row
|
||||||
|
(to be used with merge_cols)
|
||||||
|
|
||||||
|
Args:
|
||||||
|
col_a: column A (list of str)
|
||||||
|
col_b: column B (list of str)
|
||||||
|
thres: percentage of overlapping allowed
|
||||||
|
Returns:
|
||||||
|
if number of overlapping greater than threshold
|
||||||
|
"""
|
||||||
|
num_rows = len([cell for cell in col_a if cell])
|
||||||
|
assert len(col_a) == len(col_b)
|
||||||
|
conflict_count = 0
|
||||||
|
for cell_a, cell_b in zip(col_a, col_b):
|
||||||
|
if cell_a and cell_b:
|
||||||
|
conflict_count += 1
|
||||||
|
return conflict_count > num_rows * thres
|
||||||
|
|
||||||
|
|
||||||
|
def merge_cols(col_a: List[str], col_b: List[str]) -> List[str]:
|
||||||
|
"""Merge column A and B if they do not have conflict rows
|
||||||
|
|
||||||
|
Args:
|
||||||
|
col_a: column A (list of str)
|
||||||
|
col_b: column B (list of str)
|
||||||
|
Returns:
|
||||||
|
merged column
|
||||||
|
"""
|
||||||
|
for r_id in range(len(col_a)):
|
||||||
|
if col_b[r_id]:
|
||||||
|
col_a[r_id] = col_a[r_id] + " " + col_b[r_id]
|
||||||
|
return col_a
|
||||||
|
|
||||||
|
|
||||||
|
def add_index_col(csv_rows: List[List[str]]) -> List[List[str]]:
|
||||||
|
"""Add index column as the first column of the table csv_rows
|
||||||
|
|
||||||
|
Args:
|
||||||
|
csv_rows: input table
|
||||||
|
Returns:
|
||||||
|
output table with index column
|
||||||
|
"""
|
||||||
|
new_csv_rows = [["row id"] + [""] * len(csv_rows[0])]
|
||||||
|
for r_id, row in enumerate(csv_rows):
|
||||||
|
new_csv_rows.append([str(r_id + 1)] + row)
|
||||||
|
return new_csv_rows
|
||||||
|
|
||||||
|
|
||||||
|
def compress_csv(csv_rows: List[List[str]]) -> List[List[str]]:
|
||||||
|
"""Compress table csv_rows by merging sparse columns (merge_cols)
|
||||||
|
|
||||||
|
Args:
|
||||||
|
csv_rows: input table
|
||||||
|
Returns:
|
||||||
|
output: compressed table
|
||||||
|
"""
|
||||||
|
csv_cols = [[r[c_id] for r in csv_rows] for c_id in range(len(csv_rows[0]))]
|
||||||
|
to_remove_col_ids = []
|
||||||
|
last_c_id = 0
|
||||||
|
for c_id in range(1, len(csv_cols)):
|
||||||
|
if not check_col_conflicts(csv_cols[last_c_id], csv_cols[c_id]):
|
||||||
|
to_remove_col_ids.append(c_id)
|
||||||
|
csv_cols[last_c_id] = merge_cols(csv_cols[last_c_id], csv_cols[c_id])
|
||||||
|
else:
|
||||||
|
last_c_id = c_id
|
||||||
|
|
||||||
|
csv_cols = [r for c_id, r in enumerate(csv_cols) if c_id not in to_remove_col_ids]
|
||||||
|
csv_rows = [[c[r_id] for c in csv_cols] for r_id in range(len(csv_cols[0]))]
|
||||||
|
return csv_rows
|
||||||
|
|
||||||
|
|
||||||
|
def _get_rect_iou(gt_box: List[tuple], pd_box: List[tuple], iou_type=0) -> int:
|
||||||
|
"""Intersection over union on layout rectangle
|
||||||
|
|
||||||
|
Args:
|
||||||
|
gt_box: List[tuple]
|
||||||
|
A list contains bounding box coordinates of ground truth
|
||||||
|
pd_box: List[tuple]
|
||||||
|
A list contains bounding box coordinates of prediction
|
||||||
|
iou_type: int
|
||||||
|
0: intersection / union, normal IOU
|
||||||
|
1: intersection / min(areas), useful when boxes are under/over-segmented
|
||||||
|
|
||||||
|
Input format: [(x1, y1), (x2, y1), (x2, y2), (x1, y2)]
|
||||||
|
Annotation for each element in bbox:
|
||||||
|
(x1, y1) (x2, y1)
|
||||||
|
+-------+
|
||||||
|
| |
|
||||||
|
| |
|
||||||
|
+-------+
|
||||||
|
(x1, y2) (x2, y2)
|
||||||
|
|
||||||
|
Returns:
|
||||||
|
Intersection over union value
|
||||||
|
"""
|
||||||
|
|
||||||
|
assert iou_type in [0, 1], "Only support 0: origin iou, 1: intersection / min(area)"
|
||||||
|
|
||||||
|
# determine the (x, y)-coordinates of the intersection rectangle
|
||||||
|
# gt_box: [(x1, y1), (x2, y1), (x2, y2), (x1, y2)]
|
||||||
|
# pd_box: [(x1, y1), (x2, y1), (x2, y2), (x1, y2)]
|
||||||
|
x_left = max(gt_box[0][0], pd_box[0][0])
|
||||||
|
y_top = max(gt_box[0][1], pd_box[0][1])
|
||||||
|
x_right = min(gt_box[2][0], pd_box[2][0])
|
||||||
|
y_bottom = min(gt_box[2][1], pd_box[2][1])
|
||||||
|
|
||||||
|
# compute the area of intersection rectangle
|
||||||
|
interArea = max(0, x_right - x_left) * max(0, y_bottom - y_top)
|
||||||
|
|
||||||
|
# compute the area of both the prediction and ground-truth
|
||||||
|
# rectangles
|
||||||
|
gt_area = (gt_box[2][0] - gt_box[0][0]) * (gt_box[2][1] - gt_box[0][1])
|
||||||
|
pd_area = (pd_box[2][0] - pd_box[0][0]) * (pd_box[2][1] - pd_box[0][1])
|
||||||
|
|
||||||
|
# compute the intersection over union by taking the intersection
|
||||||
|
# area and dividing it by the sum of prediction + ground-truth
|
||||||
|
# areas - the interesection area
|
||||||
|
if iou_type == 0:
|
||||||
|
iou = interArea / float(gt_area + pd_area - interArea)
|
||||||
|
elif iou_type == 1:
|
||||||
|
iou = interArea / max(min(gt_area, pd_area), 1)
|
||||||
|
|
||||||
|
# return the intersection over union value
|
||||||
|
return iou
|
||||||
|
|
||||||
|
|
||||||
|
def get_table_from_ocr(ocr_list: List[dict], table_list: List[dict]):
|
||||||
|
"""Get list of text lines belong to table regions specified by table_list
|
||||||
|
|
||||||
|
Args:
|
||||||
|
ocr_list: list of OCR output in Casia format (Flax)
|
||||||
|
table_list: list of table output in Casia format (Flax)
|
||||||
|
|
||||||
|
Returns:
|
||||||
|
_type_: _description_
|
||||||
|
"""
|
||||||
|
table_texts = []
|
||||||
|
for table in table_list:
|
||||||
|
if table["type"] != "table":
|
||||||
|
continue
|
||||||
|
cur_table_texts = []
|
||||||
|
for ocr in ocr_list:
|
||||||
|
_iou = _get_rect_iou(table["location"], ocr["location"], iou_type=1)
|
||||||
|
if _iou > 0.8:
|
||||||
|
cur_table_texts.append(ocr["text"])
|
||||||
|
table_texts.append(cur_table_texts)
|
||||||
|
|
||||||
|
return table_texts
|
||||||
|
|
||||||
|
|
||||||
|
def make_markdown_table(array: List[List[str]]) -> str:
|
||||||
|
"""Convert table rows in list format to markdown string
|
||||||
|
|
||||||
|
Args:
|
||||||
|
Python list with rows of table as lists
|
||||||
|
First element as header.
|
||||||
|
Example Input:
|
||||||
|
[["Name", "Age", "Height"],
|
||||||
|
["Jake", 20, 5'10],
|
||||||
|
["Mary", 21, 5'7]]
|
||||||
|
Returns:
|
||||||
|
String to put into a .md file
|
||||||
|
"""
|
||||||
|
array = compress_csv(array)
|
||||||
|
array = add_index_col(array)
|
||||||
|
markdown = "\n" + str("| ")
|
||||||
|
|
||||||
|
for e in array[0]:
|
||||||
|
to_add = " " + str(e) + str(" |")
|
||||||
|
markdown += to_add
|
||||||
|
markdown += "\n"
|
||||||
|
|
||||||
|
markdown += "| "
|
||||||
|
for i in range(len(array[0])):
|
||||||
|
markdown += str("--- | ")
|
||||||
|
markdown += "\n"
|
||||||
|
|
||||||
|
for entry in array[1:]:
|
||||||
|
markdown += str("| ")
|
||||||
|
for e in entry:
|
||||||
|
to_add = str(e) + str(" | ")
|
||||||
|
markdown += to_add
|
||||||
|
markdown += "\n"
|
||||||
|
|
||||||
|
return markdown + "\n"
|
||||||
|
|
||||||
|
|
||||||
|
def parse_csv_string_to_list(csv_str: str) -> List[List[str]]:
|
||||||
|
"""Convert CSV string to list of rows
|
||||||
|
|
||||||
|
Args:
|
||||||
|
csv_str: input CSV string
|
||||||
|
|
||||||
|
Returns:
|
||||||
|
Output table in list format
|
||||||
|
"""
|
||||||
|
io = StringIO(csv_str)
|
||||||
|
csv_reader = csv.reader(io, delimiter=",")
|
||||||
|
rows = [row for row in csv_reader]
|
||||||
|
return rows
|
||||||
|
|
||||||
|
|
||||||
|
def format_cell(cell: str, length_limit: Optional[int] = None) -> str:
|
||||||
|
"""Format cell content by remove redundant character and enforce length limit
|
||||||
|
|
||||||
|
Args:
|
||||||
|
cell: input cell text
|
||||||
|
length_limit: limit of text length.
|
||||||
|
|
||||||
|
Returns:
|
||||||
|
new cell text
|
||||||
|
"""
|
||||||
|
cell = cell.replace("\n", " ")
|
||||||
|
if length_limit:
|
||||||
|
cell = cell[:length_limit]
|
||||||
|
return cell
|
||||||
|
|
||||||
|
|
||||||
|
def extract_tables_from_csv_string(
|
||||||
|
csv_content: str, table_texts: List[List[str]]
|
||||||
|
) -> Tuple[List[str], str]:
|
||||||
|
"""Extract list of table from FullOCR output
|
||||||
|
(csv_content) with the specified table_texts
|
||||||
|
|
||||||
|
Args:
|
||||||
|
csv_content: CSV output from FullOCR pipeline
|
||||||
|
table_texts: list of table texts extracted
|
||||||
|
from get_table_from_ocr()
|
||||||
|
|
||||||
|
Returns:
|
||||||
|
List of tables and non-text content
|
||||||
|
"""
|
||||||
|
rows = parse_csv_string_to_list(csv_content)
|
||||||
|
used_row_ids = []
|
||||||
|
table_csv_list = []
|
||||||
|
for table in table_texts:
|
||||||
|
cur_rows = []
|
||||||
|
for row_id, row in enumerate(rows):
|
||||||
|
scores = [
|
||||||
|
any(cell in cell_reference for cell in table)
|
||||||
|
for cell_reference in row
|
||||||
|
if cell_reference
|
||||||
|
]
|
||||||
|
score = sum(scores) / len(scores)
|
||||||
|
if score > 0.5 and row_id not in used_row_ids:
|
||||||
|
used_row_ids.append(row_id)
|
||||||
|
cur_rows.append([format_cell(cell) for cell in row])
|
||||||
|
if cur_rows:
|
||||||
|
table_csv_list.append(make_markdown_table(cur_rows))
|
||||||
|
else:
|
||||||
|
print("table not matched", table)
|
||||||
|
|
||||||
|
non_table_rows = [
|
||||||
|
row for row_id, row in enumerate(rows) if row_id not in used_row_ids
|
||||||
|
]
|
||||||
|
non_table_text = "\n".join(
|
||||||
|
" ".join(format_cell(cell) for cell in row) for row in non_table_rows
|
||||||
|
)
|
||||||
|
return table_csv_list, non_table_text
|
||||||
|
|
||||||
|
|
||||||
|
def strip_special_chars_markdown(text: str) -> str:
|
||||||
|
"""Strip special characters from input text in markdown table format"""
|
||||||
|
return text.replace("|", "").replace(":---:", "").replace("---", "")
|
||||||
|
|
||||||
|
|
||||||
|
def markdown_to_list(markdown_text: str, pad_to_max_col: Optional[bool] = True):
|
||||||
|
rows = []
|
||||||
|
lines = markdown_text.split("\n")
|
||||||
|
markdown_lines = [line.strip() for line in lines if " | " in line]
|
||||||
|
|
||||||
|
for row in markdown_lines:
|
||||||
|
tmp = row
|
||||||
|
# Get rid of leading and trailing '|'
|
||||||
|
if tmp.startswith("|"):
|
||||||
|
tmp = tmp[1:]
|
||||||
|
if tmp.endswith("|"):
|
||||||
|
tmp = tmp[:-1]
|
||||||
|
|
||||||
|
# Split line and ignore column whitespace
|
||||||
|
clean_line = tmp.split("|")
|
||||||
|
if not all(c == "" for c in clean_line):
|
||||||
|
# Append clean row data to rows variable
|
||||||
|
rows.append(clean_line)
|
||||||
|
|
||||||
|
# Get rid of syntactical sugar to indicate header (2nd row)
|
||||||
|
rows = [row for row in rows if "---" not in " ".join(row)]
|
||||||
|
max_cols = max(len(row) for row in rows)
|
||||||
|
if pad_to_max_col:
|
||||||
|
rows = [row + [""] * (max_cols - len(row)) for row in rows]
|
||||||
|
return rows
|
||||||
|
|
||||||
|
|
||||||
|
def parse_markdown_text_to_tables(text: str) -> Tuple[List[str], List[str]]:
|
||||||
|
"""Convert markdown text to list of non-table spans and table spans
|
||||||
|
|
||||||
|
Args:
|
||||||
|
text: input markdown text
|
||||||
|
|
||||||
|
Returns:
|
||||||
|
list of table spans and non-table spans
|
||||||
|
"""
|
||||||
|
# init empty tables and texts list
|
||||||
|
tables = []
|
||||||
|
texts = []
|
||||||
|
|
||||||
|
# split input by line break
|
||||||
|
lines = text.split("\n")
|
||||||
|
cur_table = []
|
||||||
|
cur_text: List[str] = []
|
||||||
|
for line in lines:
|
||||||
|
line = line.strip()
|
||||||
|
if line.startswith("|"):
|
||||||
|
if len(cur_text) > 0:
|
||||||
|
texts.append(cur_text)
|
||||||
|
cur_text = []
|
||||||
|
cur_table.append(line)
|
||||||
|
else:
|
||||||
|
# add new table to the list
|
||||||
|
if len(cur_table) > 0:
|
||||||
|
tables.append(cur_table)
|
||||||
|
cur_table = []
|
||||||
|
cur_text.append(line)
|
||||||
|
|
||||||
|
table_texts = ["\n".join(table) for table in tables]
|
||||||
|
non_table_texts = ["\n".join(text) for text in texts]
|
||||||
|
return table_texts, non_table_texts
|
||||||
BIN
tests/resources/dummy.xlsx
Normal file
BIN
tests/resources/dummy.xlsx
Normal file
Binary file not shown.
1
tests/resources/fullocr_sample_output.json
Normal file
1
tests/resources/fullocr_sample_output.json
Normal file
File diff suppressed because one or more lines are too long
131
tests/resources/policy.md
Normal file
131
tests/resources/policy.md
Normal file
@@ -0,0 +1,131 @@
|
|||||||
|
# 5 年ごと配当付特定状態保障定期保険特約条項 目次
|
||||||
|
|
||||||
|
## 1. この特約の概要
|
||||||
|
|
||||||
|
第 1 条 特約保険金の支払
|
||||||
|
|
||||||
|
第 2 条 特約保険金の支払に関する補則
|
||||||
|
|
||||||
|
第 3 条 特約保険金の免責事由に該当した場合の取扱
|
||||||
|
|
||||||
|
第 4 条 特約保険金の請求、支払時期および支払場所
|
||||||
|
|
||||||
|
第 5 条 特約の保険料払込の免除
|
||||||
|
|
||||||
|
第 6 条 特約の締結
|
||||||
|
|
||||||
|
第 7 条 特約の責任開始期
|
||||||
|
|
||||||
|
第 8 条 特約の保険期間および保険料払込期間
|
||||||
|
|
||||||
|
第 9 条 特約の保険料の払込
|
||||||
|
|
||||||
|
第 10 条 猶予期間中の保険事故亡保険料の取扱
|
||||||
|
|
||||||
|
第 11 条 特約の失効
|
||||||
|
|
||||||
|
第 12 条 特約の復活
|
||||||
|
|
||||||
|
第 13 条 告知義務
|
||||||
|
|
||||||
|
第 14 条 告知義務違反による解除
|
||||||
|
|
||||||
|
第 15 条 特約を解除できない場合
|
||||||
|
|
||||||
|
第 16 条 重大事由による解除
|
||||||
|
|
||||||
|
第 17 条 特約の解約
|
||||||
|
|
||||||
|
第 18 条 特約の返還金
|
||||||
|
|
||||||
|
第 19 条 特約の消滅とみなす場合
|
||||||
|
|
||||||
|
第 20 条 債権者等により特約が解約される場合の取扱
|
||||||
|
|
||||||
|
第 21 条 特約保険金額の減額
|
||||||
|
|
||||||
|
第 22 条 特約の更新
|
||||||
|
|
||||||
|
第 23 条 特約の契約者配当金
|
||||||
|
|
||||||
|
第 24 条 主契約の内容变更に伴う特約の取扱
|
||||||
|
|
||||||
|
第 25 条 主契約について保険料の自動貸付の規定を適用 する場合の取扱
|
||||||
|
|
||||||
|
第 26 条 主契約を払済保険に变更する場合の取扱
|
||||||
|
|
||||||
|
第 27 条 法令等の改正等に伴う特約障害保険金および特 約介護保険金の支払事由に関する規定の变更
|
||||||
|
|
||||||
|
第 28 条 管轄裁判所
|
||||||
|
|
||||||
|
第 29 条 契約内容の登録
|
||||||
|
|
||||||
|
第 30 条 主約款の規定の準用
|
||||||
|
|
||||||
|
第 31 条 5 年ごと配当付定期保険または 5 年ごと利差配 当付定期保険に付加した場合の特則
|
||||||
|
|
||||||
|
第 32 条 5 年ごと配当付生存給付金付定期保険または 5 年己゙と利差配当付生存給付金付定期保険に付加 した場合の特則
|
||||||
|
第 33 条 5 年ごと配当付逓増定期保険または 5 年ごと利 差配当付逓增定期保険沉付加した場合の特則
|
||||||
|
|
||||||
|
第 34 条 5 年ごと配当付養老保険または 5 年ごと利差配 当付養老保険に付加した場合の特則
|
||||||
|
|
||||||
|
第 35 条 5 年ごと配当付終身保険に 5 年ごと配当付年金 支払移行特約等を付加した場合または 5 年ごと 利差配当付終身保険厄 5 年己゙と利差配当付年金 支払移行特約等を付加した場合の特約の取扱
|
||||||
|
|
||||||
|
第 36 条 保険料払込期間が終身の 5 年ごと配当付終身保 険または保険料払込期間が終身の 5 年ごと利差 配当付終身保険尺付加した場合の特則
|
||||||
|
|
||||||
|
第 37 条 5 年ごと配当付更新型終身移行保険または 5 年 ごと利差配当付更新型終身移行保険に付加した 場合の特則
|
||||||
|
|
||||||
|
第 38 条 5 年ごと配当付更新型終身移行保険または 5 年 ごと利差配当付更新型終身移行保険に 5 年ごと 配当付年金支払移行特約等を付加した場合の特 約の取扱
|
||||||
|
|
||||||
|
第 39 条 5 年ごと配当付介護年金終身保障保険または 5 年ごと利差配当付介護年金終身保障保険に付加 した場合の特則
|
||||||
|
|
||||||
|
第 40 条 5 年己゙と配当付終身医療保険または 5 年ごと利 差配当付経身医療保険汇付加した場合の特則
|
||||||
|
|
||||||
|
第 41 条 5 年ごと配当付介護年金保険(解約返還金なし 型)に付加した場合の特則
|
||||||
|
|
||||||
|
第 42 条 転換後契約または变更後契約に付加した場合の 特則
|
||||||
|
|
||||||
|
第 43 条 転換特約、部分保障变更特約または家族内保障 承継特約を付加した場合の特則
|
||||||
|
|
||||||
|
第 44 条 特別条件を付けた場合の特則
|
||||||
|
|
||||||
|
第 45 条 契約日が平成 22 年 3 月 1 日以前の主契約に付加 した場合の特則
|
||||||
|
|
||||||
|
第 46 条 契約日が平成 24 年 10 月 1 日以前の主契約に付加 した場合の特約特定疾病保険金、特約障害保険 金および特約介護保険金の代理請求
|
||||||
|
|
||||||
|
## 2. 5 年ごと配当付特定状態保障定期保険特約条項
|
||||||
|
|
||||||
|
## 3. (この特約の概要)
|
||||||
|
|
||||||
|
(2015 年 5 月 21 日改正)
|
||||||
|
|
||||||
|
この特約は、つぎの給付を行うことを主な内容とするものです。なお、特約死亡保険金額、特約特定疾病保険金額、特 約障害保険金額および特約介護保険金額は同額です。
|
||||||
|
|
||||||
|
| | 給付の内容 |
|
||||||
|
| :----------------: | :-----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------: |
|
||||||
|
| 特約死亡保険金 | 被保険者がこの特約の保険期間中に死亡したときに支払います。 |
|
||||||
|
| 特約特定疾病保険金 | $\begin{array}{l}\text { 被保険者がこの特約の保険期間中に特定の疾病(悪性新生物(がん)、急性心筋梗塞または脳 } \\ \text { 卒中)により所定の状態に該当したときに支払います。 }\end{array}$ |
|
||||||
|
| 特約障害保険金 |  |
|
||||||
|
| 特約介護保険金 | 被保険者がこの特約の保険期間中に傷害または疾病により所定の要介護状態に該当したとき |
|
||||||
|
|
||||||
|
1。この特約において支払う特約保険金はつぎのとおりです。
|
||||||
|
|
||||||
|
| | $\begin{array}{l}\text { 特約保険金を支払う場合(以下「支払事由」 } \\ \text { といいます。) }\end{array}$ | 支払額 | 受取人 | $\begin{array}{l}\text { 支払事由に該当しても特約保険金を支払 } \\ \text { わない場合 (以下「免責事由」といいます。) }\end{array}$ |
|
||||||
|
| :-------------------------------------------------------------------------------------------------------------------------------------------------------: | :-----------------------------------------------------------------------------------------------------------------------------: | :-----------------------------------------------------------------------------------------------------------------------: | :-----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------: | :----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------: |
|
||||||
|
| $\begin{array}{l}\text { 特 } \\ \text { 約 } \\ \text { 死 } \\ 亡 \\ \text { 亡 } \\ \text { 保 } \\ \text { 険 } \\ \text { 金 }\end{array}$ | $\begin{array}{l}\text { 被保険者がこの特約の保険期間中に死亡し } \\ \text { たとき }\end{array}$ | $\begin{array}{l}\text { 特 } \\ \text { 約 } \\ \text { 保 } \\ \text { 険 } \\ \text { 金 } \\ \text { 額 }\end{array}$ | $\begin{array}{l}\text { 特 } \\ \text { 絢 } \\ \text { 㨐 } \\ \text { 険 } \\ \text { 善 } \\ \text { 聚 }\end{array}$ | $\begin{array}{l}\text { つぎのいずれかにより左記の支払事由が } \\ \text { 生じたとき } \\ \text { (1) この特約の責任開始期(復活の取扱が } \\ \text { 行われた後は、最後の復活の際の責任開 } \\ \text { 始期。以下同じ。)の属するもからその } \\ \text { 日を含めて } 3 \text { 年以内の自殺 } \\ \text { (2) 保険契約者または特約死亡保険金受 } \\ \text { 取人の故意 } \\ \text { (3) 戦争その他の变乱 }\end{array}$ |
|
||||||
|
| $\begin{array}{l}\text { 特 } \\ \text { 約 } \\ \text { 特 } \\ \text { 定 } \\ \text { 疾 } \\ \text { 病 } \\ \text { 除 } \\ \text { 金 }\end{array}$ |  | | $\begin{array}{l}\text { 特 } \\ \text { 約 } \\ \text { 特 } \\ \text { 定 } \\ \text { 疾 } \\ \text { 病 } \\ \text { 保 } \\ \text { 険 } \\ \text { 金 } \\ \text { 受 } \\ \text { 取 } \\ \text { 人 }\end{array}$ | + |
|
||||||
|
| $\begin{array}{l}\text { 特 } \\ \text { 約 } \\ \text { 障 } \\ \text { 害 } \\ \text { 保 } \\ \text { 険 } \\ \text { 金 }\end{array}$ |  | | $\begin{array}{l}\text { 特 } \\ \text { 約 } \\ \text { 障 } \\ \text { 害 } \\ \text { 保 } \\ \text { 険 } \\ \text { 金 } \\ \text { 受 } \\ \text { 取 } \\ \text { 人 }\end{array}$ |  |
|
||||||
|
|
||||||
|
| | 支払事由 | 支払額 | 受取人 | 免責事由 |
|
||||||
|
| :---------------------------------------------------------------------------------------------------------------------------------------: | :----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------: | :-----------------------------------------------------------------------------------------------------------------------: | :---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------: | :-------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------: |
|
||||||
|
| $\begin{array}{l}\text { 特 } \\ \text { 約 } \\ \text { 介 } \\ \text { 護 } \\ \text { 保 } \\ \text { 険 } \\ \text { 金 }\end{array}$ | $\begin{array}{l}\text { 被保険者がこの特約の責任開始期以後の傷 } \\ \text { 害または疾病を原因として、この特約の保 } \\ \text { 険期間中に要介護状態(表4)に該当した } \\ \text { とき }\end{array}$ | $\begin{array}{l}\text { 特 } \\ \text { 約 } \\ \text { 保 } \\ \text { 険 } \\ \text { 金 } \\ \text { 額 }\end{array}$ | $\begin{array}{l}\text { 特 } \\ \text { 約 } \\ \text { 介 } \\ \text { 護 } \\ \text { 保 } \\ \text { 険 } \\ \text { 金 } \\ \text { 受 } \\ \text { 取 } \\ \text { 人 }\end{array}$ | $\begin{array}{l}\text { つぎのいずれかにより左記の支払事由が生 } \\ \text { じたとき } \\ \text { (1) 保険契約者または被保険者の故意また } \\ \text { は重大な過失 } \\ \text { (2) 被保険者の犯罪行為 } \\ \text { (3) 被保険者の精神障害を原因とする事故 } \\ \text { (4) 被保険者の泥酔の状態を原因とする事 } \\ \text { 故 } \\ \text { (5) 被保険者が法令に定める運転資格を持 } \\ \text { たないで運転している間に生じた事故 } \\ \text { (6) 被保険者が法令に定める酒気帯び運転 } \\ \text { またはこれに相当する運転をしている間 } \\ \text { に生じた事故 } \\ \text { (7) 被保険者の薬物依存 } \\ \text { (8) 地震、噴火または津波 } \\ \text { (9) 戦争その他の变乱 }\end{array}$ |
|
||||||
|
|
||||||
|
2. 第 1 項の特約特定疾病保険金の支払事由の(1)に該当した場合でも、この特約の責任開始期の属する日からその日を含 めて 90 日以内に乳房の悪性新生物(表 1 中、基本分類コード C 50 の悪性新生物。以下同じ。)に䍜患し、医師により診断 確定されたときは、当会社は、特約特定疾病保険金を支払いません。ただし、その後(乳房の悪性新生物についてはこ の特約の責任開始期の属する日からその日を含めて 90 日経過後)、この特約の保険期間中に、被保険者がその乳房の悪性 新生物と因果関係のない悪性新生物(表 1)に罹患し、医師により診断確定されたときは、特約特定疾病保険金を支払 います。
|
||||||
|
|
||||||
|
## 4. 表 1 対象となる悪性新生物、急性心筋梗塞、脳卒中
|
||||||
|
|
||||||
|
対象となる悪性新生物、急性心筋梗塞、脳卒中とは、次表によって定義づけられる疾病とし、かつ、平成 21 年 3 月 23 日 総務省告示第 176 号にもとづ<厚生労働省大臣官房統計情報部編「疾病、傷害および死因統計分類提要ICD-10(2003 年版)準拠」に記載された分類項目中、次表の基本分類コードに規定される内容によるものをいいます。
|
||||||
|
|
||||||
|
| 疾 病 名 | 疾 病 の 定 義 | 分 類 項 目 |  |
|
||||||
|
| :--------: | :-----------------------------------------------------------------------------------------------------------------------------: | :-----------------------------------------------------------------------------------------------------------------------------: | :--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------: |
|
||||||
|
| 悪性新生物 |  | 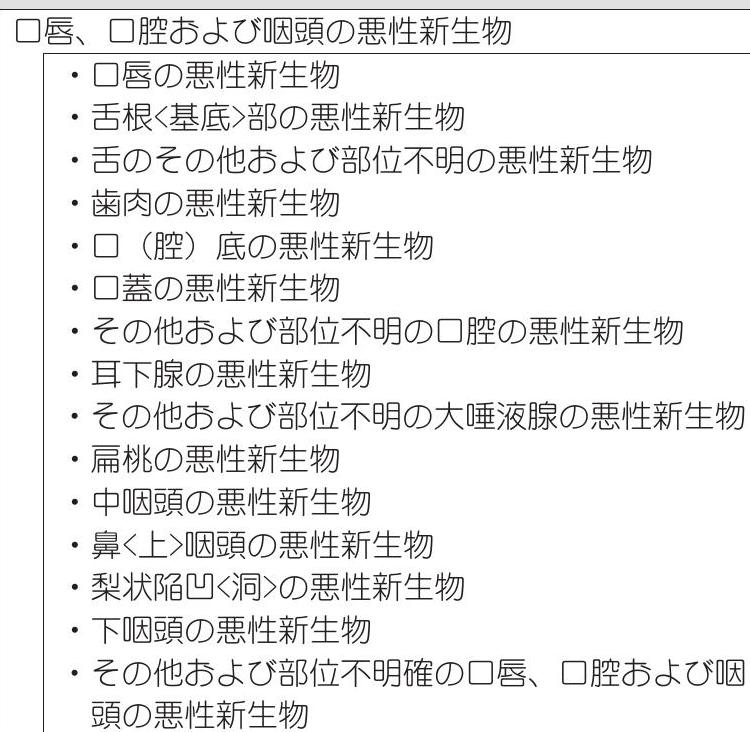 | $\begin{array}{l}\mathrm{C} 00-\mathrm{C} 1 \\ \mathrm{C} 00 \\ \mathrm{C} 01 \\ \mathrm{C} 02 \\ \mathrm{C} 03 \\ \mathrm{C} 04 \\ \mathrm{C} 05 \\ \mathrm{C} 06 \\ \mathrm{C} 07 \\ \mathrm{C} 08 \\ \mathrm{C} 09 \\ \mathrm{C} 10 \\ \mathrm{C} 11 \\ \mathrm{C} 12 \\ \mathrm{C} 13 \\ \mathrm{C} 14\end{array}$ |
|
||||||
45
tests/test_table_reader.py
Normal file
45
tests/test_table_reader.py
Normal file
@@ -0,0 +1,45 @@
|
|||||||
|
import json
|
||||||
|
from pathlib import Path
|
||||||
|
|
||||||
|
import pytest
|
||||||
|
|
||||||
|
from kotaemon.loaders import MathpixPDFReader, OCRReader, PandasExcelReader
|
||||||
|
|
||||||
|
input_file = Path(__file__).parent / "resources" / "dummy.pdf"
|
||||||
|
input_file_excel = Path(__file__).parent / "resources" / "dummy.xlsx"
|
||||||
|
|
||||||
|
|
||||||
|
@pytest.fixture
|
||||||
|
def fullocr_output():
|
||||||
|
with open(Path(__file__).parent / "resources" / "fullocr_sample_output.json") as f:
|
||||||
|
fullocr = json.load(f)
|
||||||
|
return fullocr
|
||||||
|
|
||||||
|
|
||||||
|
@pytest.fixture
|
||||||
|
def mathpix_output():
|
||||||
|
with open(Path(__file__).parent / "resources" / "policy.md") as f:
|
||||||
|
content = f.read()
|
||||||
|
return content
|
||||||
|
|
||||||
|
|
||||||
|
def test_ocr_reader(fullocr_output):
|
||||||
|
reader = OCRReader()
|
||||||
|
documents = reader.load_data(input_file, response_content=fullocr_output)
|
||||||
|
table_docs = [doc for doc in documents if doc.metadata.get("type", "") == "table"]
|
||||||
|
assert len(table_docs) == 4
|
||||||
|
|
||||||
|
|
||||||
|
def test_mathpix_reader(mathpix_output):
|
||||||
|
reader = MathpixPDFReader()
|
||||||
|
documents = reader.load_data(input_file, response_content=mathpix_output)
|
||||||
|
table_docs = [doc for doc in documents if doc.metadata.get("type", "") == "table"]
|
||||||
|
assert len(table_docs) == 4
|
||||||
|
|
||||||
|
|
||||||
|
def test_excel_reader():
|
||||||
|
reader = PandasExcelReader()
|
||||||
|
documents = reader.load_data(
|
||||||
|
input_file_excel,
|
||||||
|
)
|
||||||
|
assert len(documents) == 1
|
||||||
Reference in New Issue
Block a user